CS 136 - Elementary Algorithm Design and Data Abstraction
TTh 2:30PM - 3:50PM
MC 4059
Nomair Naeem
1 | Functional C
1.1 | History and Expressions
C has no exponentiation operator Each operator is either left or right associative. Multiplication is left-associative:
1.2 | Identifiers and Functions
C uses snake_case
C is a static type system
Leading zeros in C are bad - evaluated in octal (010=8, 0x10=16)
No nested functions
1.3 | The main function and tracing code
Files in a C program
- Implementation files
.c - Header files
.h - Compiled files
.o / .ll - Executable files
a.out
Printf
#include <stdio.h> // alternatively include "cs136.h"
int main(void) {
printf("Hello World!");
return 0;
}trace_int() traces an expression
Functions must be declared before they are called
int my_add(int a, int b); // function DECLARATION
int my_add(int a, int b) { // function DEFINITION
return a + b;
}1.4 | Testing Code
Boolean expressions evaluate to 0 for false and 1 for true
assert(my_add(1, 1) == 2);
Assertion `my_add(1, 1) == 2’ failed.
// Infeasible Requirements
// my_function(n) ....
// requires: n is a prime number [not asserted]1.5 | Statements and control flow
Do not use: switch, goto
2 | Imperative C
2.1 | I/O and output side effects
2.2 | Mutation side effects
Variables and Variable Mutation
x = 5;
y0 = x++;
// y0 = 5
y1 = ++x;
// y1 = 62.3 | More Mutation
2.4 | Input side effects
// Using scanf, write a recursive function twice_all that reads all numbers from stdin,
// multiplies each by 2, and prints them.
#include "cs136.h"
void twice_all (){
int val = 0;
if (1 == scanf("%d", &val)){
printf("%d\n", 2*val);
twice_all();
}
}
int main(void) {
twice_all();
}2.5 | I/O Testing
Ternary Operator: The value of
X ? Y : Zwill be Y if X is non-zero, and Z if X is zero.
#include "cs136.h"
// Write a testing harness for fact2.
// fact2(n) Calculate n!.
// requires: n >= 0
void test_fact2(void) {
int x = 0;
if (1 == scanf("%d", &x)){
printf("%d\n", fact2(x));
test_fact2();
}
}
int fact2(int n) {
assert(n >= 0);
return n ? n * fact2(n - 1) : 1;
}#include "cs136.h"
// Write and test the function partsum.
void partsum (acc){
int val = 0;
if (1 == scanf("%d", &val)){
acc += val;
printf("%d\n", acc);
partsum(acc);
}
}
int main(void) {
partsum(0);
}#include "cs136.h"
// Write and test the function downup.
void downup (n){
if (n == 0){
printf("0\n");
return;
} else {
printf ("%d\n", n);
downup(n-1);
printf ("%d\n", n);
}
}
int main (void){
downup(2);
}3 | Model
3.1 | Control Flow
Control Flow = models how programs are executed
- Program location = where the execution is currently occurring (usually
main) - Program counter (hardware) = contains the address within the machine code
Types
- Compound statements (blocks)
- Function calls
- Conditional (
if) - Iteration (loops)
3.2 | Memory and Variables
Bit = 0 or 1 Byte = 8 bits = possible states
Int ('%d')
- The size of an
intis 4 bytes = 32 bits = in size unsigned intvariables are not signed :o
Char ('&c')
- The size of a
charis 1 byte = 8 bits = in size - The range of values is -128 to 127
- ASCII is used to encode characters 0 to 126
- Unicode supports 100,000+ chars worldwide
- We use UTF-8 to encode it, where ASCII codes only use 1 byte
Float ('%f')
- A 32 bit
floatuses 24 bits for the mantissa (after the decimal) and 8 bits for the exponent (before) - A 64 bit
doubleuses (53+11)
3.3 | Memory - Structures
#include "cs136.h"
struct posn { // name of the structure
int x; // type and field names
int y;
}; // don't forget this ;
int main(void) {
struct posn p = {1, 2};
trace_int(p.x);
trace_int(p.y);
}3.4 | Memory - Sections
5 sections (or “regions”) of memory
- Code
- Read-only data (const variable)
- Global data
- Heap
- Stack (local constants)
Source code → compiles machine code
Machine code (file) → runs using the loader
3.5 | Stacks and Recursion in C
Function Calls
- When a function is called, the program location “jumps” from the current location to the start of the function
returnchanges the program location to go back to the most recent calling function (where it “jumped from”)- C needs to track where it “jumped from” so it knows where to
returnto
Stacks
- Call Stack
- Return Address = line number (eg. `main: 13’)
- Stack Frames
- Argument Values
- Local Variables
- Return Address
- C makes a copy of each argument and places the copy in the stack frame - the “pass by value” convention
Calling a function
- a stack frame is created (“pushed” onto the Stack)
- the current program location is placed in the stack frame as the return address
- a copy of each of the arguments is placed in the stack frame
- the program location is changed to the start of the new function
- the initial values of local variables are set when their definition is encountered
Return
- the current program location is changed back to the return address (which is retrieved from the stack frame)
- the stack frame is removed (“popped” from the Stack memory area)
Memory Sections (high to low)
- Stack
- Heap
- Global Data
- Read-Only Data
- Code
Scope vs Memory
- Scope = when a variable is visible or accessible
- Memory = Part of the C model
int foo(void) {
// SNAPSHOT HERE (at line 2)
// 5 variables are in memory,
// but none are in scope
int a = 1;
{
int b = 2;
}
return a;
}
const int c = 3;
int d = 4;
int main(void) {
int e = 5;
foo();
}GLOBAL DATA:
d: 4
READ-ONLY DATA:
c: 3
STACK:
=========================
foo:
a: ???
b: ???
return address: main:17
=========================
main:
e: 5
return address: OS
=========================
4 | Pointers
4.1 | Introduction
Address Operator (&) = provides the location of an identifier in memory (starting address)
Pointer (*) = points to a memory address, is typed
- Size is always the same (64 bits, 8 bytes)
int i = 42;
int *p = &i;Dereference operator `(*):
- Think of address (&) as “get the address of this box”
- Dereference
(*)is “follow the arrow to the next box and get its contents” &i = &*&*&i = value of i- NULL = special value corresponding to nothing (defined to be 0 or false)
- DON’T DEREFERENCE A NULL POINTER!
Dereference Selection / Arrow Operator is used for structs, because (.) has higher precedence than (*):
- `ptr→field = (*ptr).field
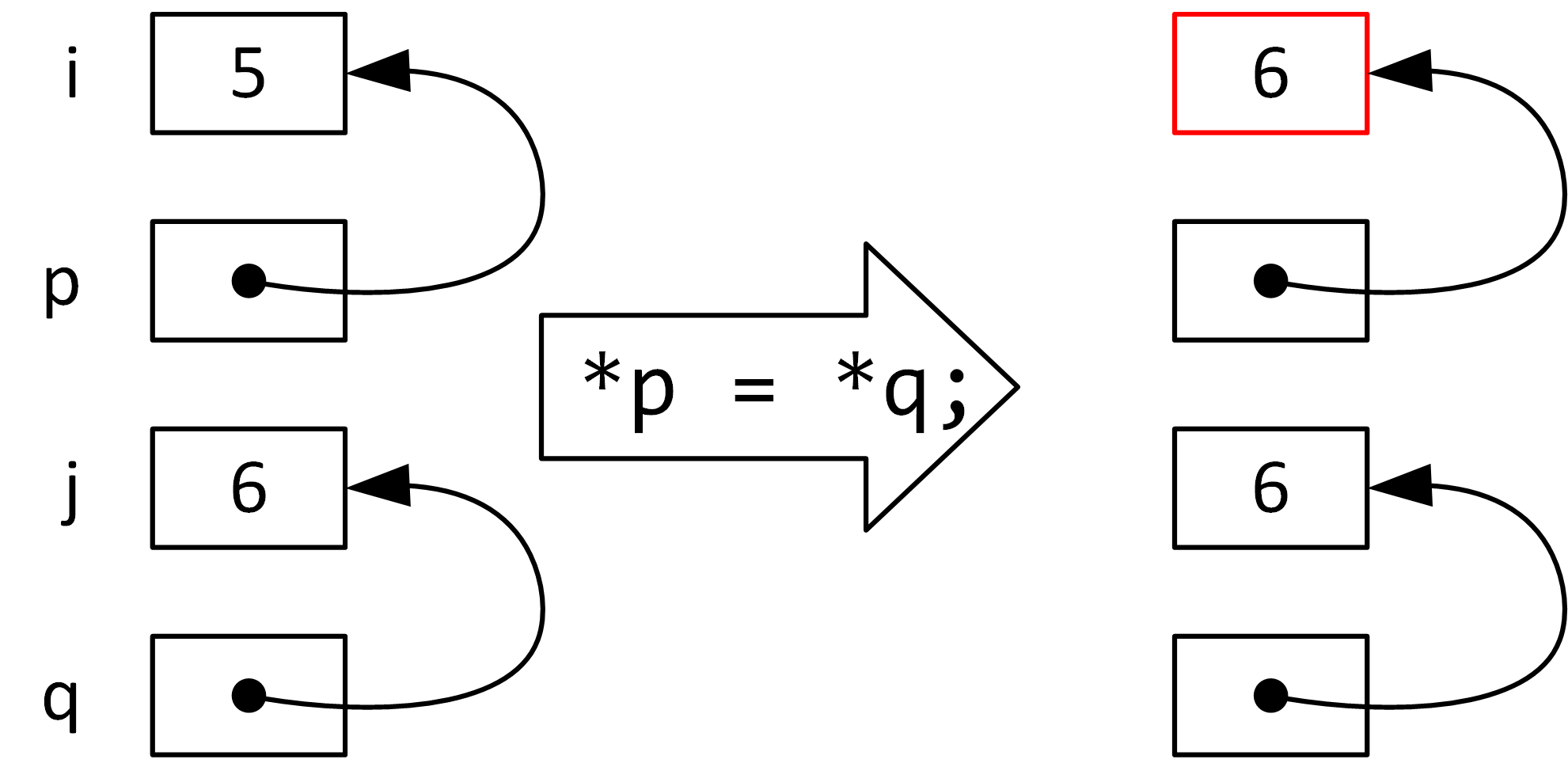
Aliasing: Same memory address can be accessed from >1 pointer variable
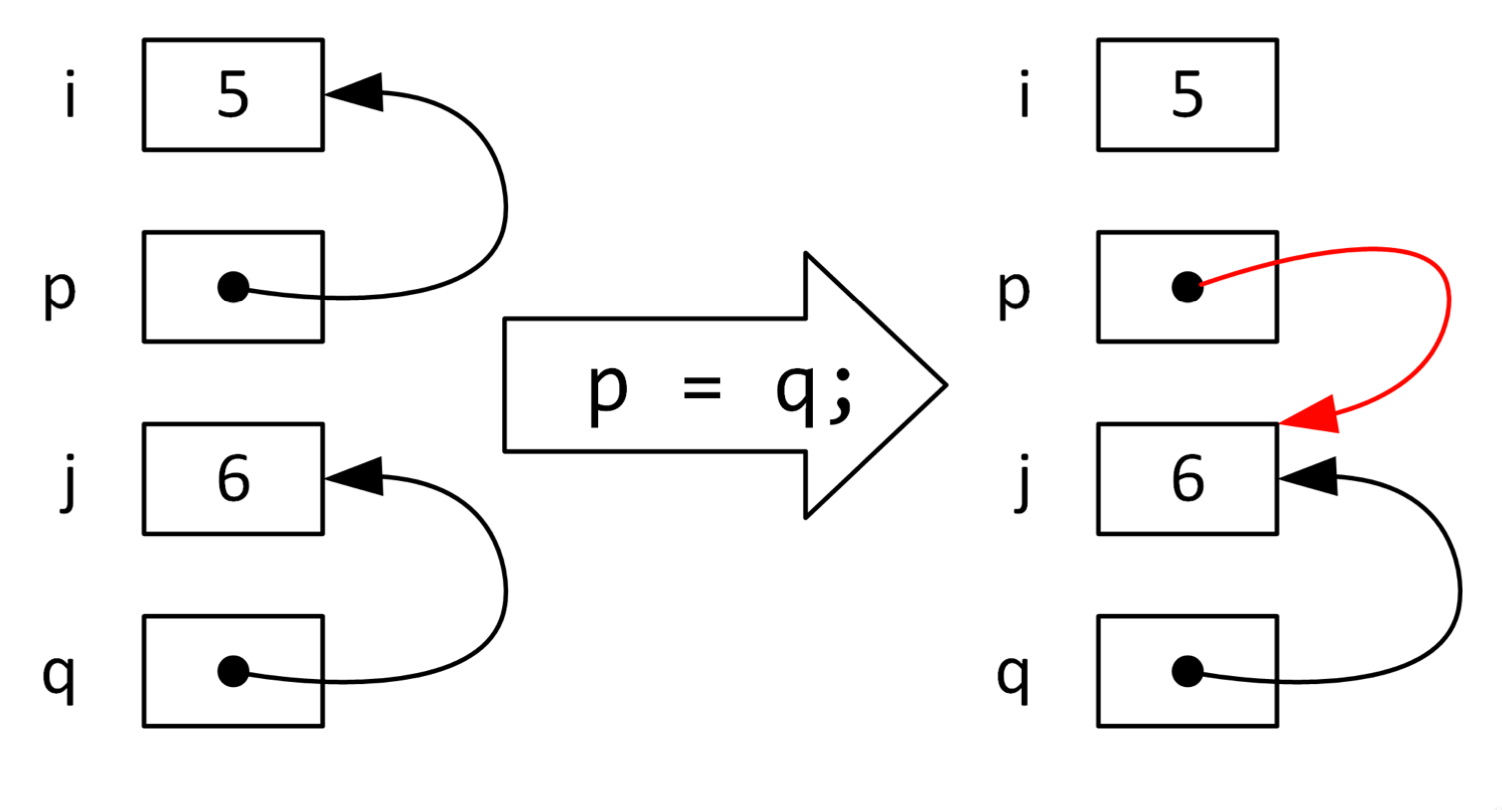 Compared to:
Compared to:
4.2 | Mutation
We now have a fourth side effect that a function may have:
- produce output
- read input
- mutate a global variable
- mutate a variable through a pointer parameter
MOTIVATION:
#include <stdio.h>
bool foo (int n){
n++;
return true;
}
int main(void) {
int i = 1;
if (foo(i)){
printf("%d", i); // this will print 1
}
return 0;
}void swap(int *px, int *py){
int temp = *px;
*px = *py;
*py = temp;
}
int main (void){
int a = 3;
int b = 4;
printf("a:%d: b%d\n", a, b);
swap(&a, &b);
printf("a:%d: b%d\n", a, b);
}// Memory snapshot for a swap pointers function
Memory snapshot after line 5
swap
px: addr_1
py: addr_2
temp: 3
r/a: main 12
main
a: 4 [addr_1]
b: 3 [addr_2]
r/a: OS
Output:
a:3; b:4
a:4; b:3
4.3 | Returning Multiple Values
C functions can only return a single value
retval = scanf("%d", &i);- We “receive” two values: the return value, and the value read in (stored in
i).
4.4 | Structures, Constants, and Functions
The rule is “const applies to the type to the left of it, unless it’s first, and then it applies to the type to the right of it”.
int *p; | p can point at any mutable integer, you can modify the int (via *p) |
|---|---|
const int *p; | p can point at any integer, you can NOT modify the integer (via *p) |
int * const p = &i; | p always points at the integer i , i must be mutable and can be modified (via *p) |
const int * const p = &i; | p always points at the integer i , you can not modify i (via *p) |
5 | Arrays and Strings
5.1 | Introduction
C only has structures and arrays as built-in “compound” data storage
Array Length
- C does not keep track of length
const int a_len = 6;
Array identifier
- When an array is used as an expression, it evaluates (“decays”) to the address / first element of the array
&a = &a[0]
Oversized Arrays
- This is like making
a[10005]for DMOJ - Keep track of the “actual” length and the maximum possible length
// This program shows how to create and use an oversized array with structures
#include <stdio.h>
struct oversized_array {
int len;
int maxlen;
int data[10];
};
void bad_print_oversized_array(struct oversized_array arr){
for (int i = 0; i < arr.len; ++i){
printf("%d\n",arr.data[i]);
}
}
void good_print_oversized_array(struct oversized_array *parr){
for (int i = 0; i < parr->len; ++i){
printf("%d\n",parr->data[i]);
}
}
int main(void){
struct oversized_array arr = {0,10};
int i = 0;
while ( scanf("%d", &i) == 1) {
if (arr.len == arr.maxlen) { // array is full
printf("Error: array is full.\n");
break;
} else {
arr.data[arr.len] = i;
++arr.len;
}
}
good_print_oversized_array(&arr);
}5.2 | Arrays & Pointers
Pointer Arithmetic: If p is a pointer, (p+1) = 1 + sizof(*p)
- Pointer + Int:
(p+i) = p + i*sizeof(*p) - Pointer - Int:
(p-i) = p - i*sizeof(*p) - Mutable Pointers:
++p EQUALS p=p+1 - You cannot add two pointers
- Pointer - Pointer:
(p-q) = ((p-q) / size(*p))- If
p=q+i, theni=p-q
- If
Pointer Arithmetic and Arrays:
- The value of an array
a = &a[0] - The value of the second element
&a[1] = (a+1) = *(a+1)
Array indexing syntax [] is an operator with performs pointer arithmetic. a[i] = *(a+i)
// sum_array with array pointer notation
int sum_array(const int *a, const int len) {
assert(a);
assert(len > 0);
int sum = 0;
for (const int *p = a; p < a + len; ++p) {
sum += *p;
}
return sum;
}5.3 | C strings
A string in C is an array of characters, terminated by a NULL CHARACTER ('\0')
Initializing Strings
- C supports automatic length declarations, such as
int a[] = {4, 8, 15, 16, 23, 42};char e[] = "cat";
Question: What is the size (in chars) of the array
char t[] = "T0\0 fu\n"? Answer: 8 (7 chars + null terminator)
Benefit of Null Termination: Don’t need to track string length!
int my_strlen (char *s){
int i = 0;
while (*s){ // 0 only if null terminator
i++; s++;
}
return i;
}String Length: strlen()
- DO NOT PUT THIS INSIDE A LOOP
- YOU’LL DIE REALLY REALLY HARD
Lexicographical Order
- Characters can be compared with <, > because of ASCII
- Strings cannot - they are compared by pointers, which are useless
- DO NOT USE == TO COMPARE STRINGS
- The
<string.h>library usesstrcmpto order lexicographically
int my_strcmp(char *s1, char *s2){
while (*s1 && *s2 && *s1==*s2){
s1++;
s2++;
}
return *s1-*s2; // null = 0
}String Copy: strcpy
strcpy(dest, src), which is part of<string.h>) overwrites the contents ofdestwith the contents ofsrc- DO NOT USE IF DEST AND SRC OVERLAP:
my_strcpy(s + 4, s);
String Concatenation:
strcat(strcat(dest, src), which is also part of<string.h>library), concatenatessrcto the end ofdest.
5.4 | String I/O
String I/O
- We use
%sandscanf, which reads until a whitespace character is encountered - This might cause a buffer overrun
- We use a width field, for instance,
scanf("%80s", name)for an array with 81 chars\
- We use a width field, for instance,
- NEVER USE SCANF WIHTOUT A MAXIMUM WIDTH SPECIFIER
scanf("%s", buf)
Read a string with whitespace: fgets(name, 81, stdin) - it’s like getline
Improperly terminated strings:
char c[3] = "cat";- BAD BECAUSE NO SPACE FOR THE NULL CHARACTER- The string library has safer versions of functions:
strnlen,strncmp,strncpyandstrncat
5.5 | String Literals
String Literals
- are just any string declared with
"" - ARE STORED IN READ-ONLY MEMORY, NOT THE STACK FRAME
Arrays vs Pointers: Not the same
- An array is more similar to a constant pointer (that cannot change what it “points at”).
int a[6] = {4, 8, 15, 16, 23, 42};int * const p = a;
6 | Modularization and ADTs
6.1 | Modularization
Modularization = dividing programs into well-defined modules
- Module = collection of functions that share a common aspect or purpose
- C modules are also called libraries
Modules vs Files
- Good style to store modules in separate files
- There’s a client which requires the functions that a module provides
- We combine (“link”) multiple machine code files
Motivation
- Re-usability
- Multiple programs can use the
funmodule
- Multiple programs can use the
- Maintainability
2. We only need to change the
funmodule to change the definition - Abstraction
- The client doesn’t need to understand what makes an integer fun
#include <stdbool.h>
#include "cs136-trace.h"
int main(void) {
trace_bool(is_fun(13));
}Calling module functions
- Implicit declaration error:
is_funis not in scope- C is statically typed and doesn’t know the return or parameter types of
is_fun
- We need to add a declaration
bool is_fun(int n);- Variable declaration starts with the
externkeyword
extern int g; // variable DECLARATION
int main(void) {
printf("%d\n", g); // this is now ok
trace_int(g);
}
int g = 7; // variable DEFINITION6.2 | Modules: Scope and Interface
Declarations extend the scope of an identifier
// g OUT of scope
extern int g; // declaration:
// g is now IN scope
int main(void) {
printf("%d\n", g); // ok
printf("%d\n", z); // INVALID: z not in scope
}
int g = 7; // definitions
int z = 2;Scope vs memory
- All global variables in all files are in memory before the program is run
Program scope
- A declaration can bring an identifier from another file into scope
- Program Scope: By default, C global identifiers are “accessible” to every file if they are declared
Module scope
static: If you want to “hide” a global identifier from other files- This restricts the scope of a global identifier to its module: module scope
- Should be used if functions and variables are not meant to be provided
- THINK OF
staticasprivate
Types of scope
- local (block) identifiers: only available inside of the function (or block)
- global identifiers
- program scope (default): available everywhere
- module scope (static): only available in the file
Module interface = list of all the functions that the module provides
- Implementation = code of the module (eg. function definitions)
- Interface = what’s provided to the client
- Overall description of the module
- Function declaration for each provided functions
- Documentation (eg. purpose) for each provided function
Start of function
- Interface
(.h)files = also known as a header file #include= inserts the contents of another file- Test client = basically testing harness
| module | functionality |
|---|---|
<assert.h> | provides the function assert |
<limits.h> | provides the constants INT_MAX and INT_MIN |
<stdbool.h> | provides the bool data type and the constants true and false |
<stdlib.h> | provides the constant NULL and abs() |
6.3 | Module Design
We want to achieve high cohesion and low coupling
- High cohesion = all functions are relating and working towards a common goal
- Low coupling = little intersection between modules
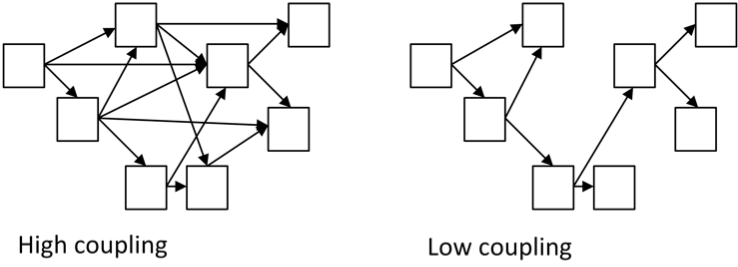
Interface vs implementation
- Advantages: safety and flexibility
- Safety: prevent the client from tampering with the data used by the module
- Flexibility: ability to change the implementation in the future
- Information hiding
- Hide implementation code, but not data
- Opaque Structures
- Client can use structure but cannot see implementation
- Only pointers to the structure can be defined
- Transparent structure = put the complete definition in the interface
.hfile
6.4 | Introduction to Abstract Data Types (ADTs)
Types of ADTs
- Dictionary (Collection ADT)
- Stack
- Queue
- Sequence
Typical stack ADT operations:
- push: adds an item to the top of the stack
- pop: removes the top item from the stack
- top: returns the top item on the stack
- is_empty: determines if the stack is empty
Typical queue ADT operations:
- add_back: adds an item to the end of the queue
- remove_front: removes the item at the front of the queue
- front: returns the item at the front
- is_empty: determines if the queue is empty
Typical sequence ADT operations:
- item_at: returns the item at a given position
- insert_at: inserts a new item at a given position
- remove_at: removes an item at a given position
- length: return the number of items in the sequence
Typical set ADT operations:
- add: adds a new item to a set
- remove: removes an item from a set
- length: return the number of items in the set
- member: returns whether or not an item is a member of a set
| ADT | Example |
|---|---|
| Dictionary | A school database collects student information in key-value pairs |
| Stack | A module that tracks browser history (LIFO) |
| Queue | A module that tracks orders for pick up (FIFO) |
6.5 | Example: Stack ADT Implementation
#include <stdio.h>
#include "cs136-trace.h"
#include "fixstack.h"
int main(void) {
struct stack s = {0};
stack_init(&s);
int n = 0;
while (scanf("%d", &n) == 1) {
stack_push(n, &s);
}
while (!stack_is_empty(&s)) {
printf("%d\n", stack_pop(&s));
}
}7 | Efficiency
7.1 | Introduction to Efficiency
7.2 | Algorithm Analysis
| Recurrence Relation | Complexity |
|---|---|
| String Functions |
| Function name | Time | Discussion |
|---|---|---|
strlen(s) | O(n) | To find the length of a string, we must traverse the string until we find the null terminator, \0. |
strcmp(s1,s2) | O(n) where n is min(strlen(s1),strlen(s2)) | In comparing two strings, we traverse both strings simultaneously and stop when the characters differ. |
strcpy(dest,src) | O(n) where n is length of `src` | The n characters in src are traversed and copied into dest. |
strcat(dest,src) | O(n+m) where n, m are lengths of `src` and dest respectively | First we find the end of dest by either traversing dest or by using strlen. Then we copy the n characters in src by either traversing them or using strcpy. |
printf("%s",str) | O(n) | Each character in the string must be printed. |
scanf("%s",str) | O(n) | Each character in the string must be read. |
7.3 | Sorting and efficiency
Selection Sort = swap the i-th smallest element into i-th position
- Best =
- Worst =
void selection_sort(int a[], int len) {
for (int i=0; i<len-1; ++i){
int index_smallest = i;
for (int j=i+1; j<len; j++){
if (a[j]<a[index_smallest]){
index_smallest=j;
}
}
swap(&a[i], &a[index_smallest]);
}
}Insertion Sort = element 1 is a sorted array, then insert element 2, then 3 …
- Best =
- Worst =
void insertion_sort(int a[], int len) {
assert(a);
assert(len > 0);
for (int i = 1; i < len; ++i) {
for (int j = i; j > 0 && a[j - 1] > a[j]; --j) {
swap(&a[j], &a[j - 1]);
}
}
}Quicksort = Select the first element as a “pivot”, move all the smaller elements to the front, all the larger elements to the back
- Best:
- Worst:
void quick_sort_range(int a[], int first, int last) {
assert(a);
if (last <= first) return; // length is <= 1
int pivot = a[first]; // first element is the pivot
int pos = last; // where to put next larger
for (int i = last; i > first; --i) {
if (a[i] > pivot) {
swap(&a[pos], &a[i]);
--pos;
}
}
swap(&a[first], &a[pos]); // put pivot in correct place
quick_sort_range(a, first, pos - 1);
quick_sort_range(a, pos + 1, last);
}
// quick_sort(a, len) sorts the elements of a in ascending order
// requires: len > 0
// effects: modifies a
void quick_sort(int a[], int len) {
assert(a);
assert(len > 0);
quick_sort_range(a, 0, len - 1);
}7.4 | Searching efficiency
int binary_search(const int target, const int a[], const int len){
int lo = 0, hi = len-1, mid = 0;
while (lo<=hi){
mid = (lo+hi)/2;
if (a[mid] < target) lo = mid+1;
if (a[mid] > target) hi = mid-1;
if (a[mid] == target) return mid;
}
return -1;
}7.5 | Algorithm Design
int max_subarray(const int a[], int len) {
assert(a);
assert(len > 0);
int maxsofar = 0;
int maxendhere = 0;
for (int i = 0; i < len; ++i) {
maxendhere = max(maxendhere + a[i], 0);
maxsofar = max(maxsofar, maxendhere);
}
return maxsofar;
}8 | Dynamic Memory and ADTs
8.1 Introduction to Dynamic Memory
malloc
- The
stdlib.hlibrary provides the memory allocation, which borrows memory from the heap - Arrays get set to random numbers when heap memory provided by malloc is uninitialized
Dynamic Arrays
malloc(len * sizeof(int))is good - always usesizeofwithmallocmallocparameter hassize_tvoid *malloc(size_t s)- it’s a void pointer- we assume
mallocis
Out of memory
- An unsuccessful call to
mallocreturnsNULLif the heap is full - Usually you have to check for this, not in this course
free
- Every block of memory obtained through
mallocmust befreed - Otherwise there’s a memory leak
- Invalid: DON’T try to access memory after it’s be freed or free it again
- Garbage collector: Most languages have it, automatically frees memory
Dangling pointers
- When a pointer points to a freed allocation
Mergesort
// merge(dest, src1, len1, src2, len2) modifies dest to contain
// the elements from both src1 and src2 in sorted order
// requires: length of dest is at least (len1 + len2) [not asserted]
// src1 and src2 are sorted [not asserted]
// effects: modifies dest
// time: O(n), where n is len1 + len2
void merge(int dest[], const int src1[], int len1,
const int src2[], int len2) {
assert(dest);
assert(src1);
assert(src2);
int pos1 = 0;
int pos2 = 0;
for (int i = 0; i < len1 + len2; ++i) {
if (pos1 == len1 || (pos2 < len2 && src2[pos2] < src1[pos1])) {
dest[i] = src2[pos2];
++pos2;
} else {
dest[i] = src1[pos1];
++pos1;
}
}
}
// merge_sort(a, len) sorts the elements of a in ascending order
// requires: a is a valid array with given len [not asserted]
// effects: modifies a
void merge_sort(int a[], int len) {
assert(a);
if (len <= 1) {
return;
}
int llen = len / 2;
int rlen = len - llen;
int *left = malloc(llen * sizeof(int));
int *right = malloc(rlen * sizeof(int));
for (int i = 0; i < llen; ++i) {
left[i] = a[i];
}
for (int i = 0; i < rlen; ++i) {
right[i] = a[i + llen];
}
merge_sort(left, llen);
merge_sort(right, rlen);
merge(a, left, llen, right, rlen);
free(left);
free(right);
}8.2 | Dynamic Memory Side Effects & String I/O
Duration
- Functions can obtain memory that persists after the function has returned
- Eg. `strcpy(dest, src)
Dynamic memory side effect
- Modifies the “state” of the heap
Manually resizing arrays
- Create a new array
- Copy items from old array to new array
- Free old array
realloc function: resizes arrays
- Assume the address passed to
reallocis freed and invalid reallocvery similar tomalloc- Using
reallocin a helper function could be dangerous
// realloc(p, newsize) resizes the memory block at p
// to be newsize and returns a pointer to the
// new location, or NULL if unsuccessful
// requires: p must be from a previous malloc/realloc
// or NULL (then realloc behaves like malloc)
// effects: the memory at p is invalid (freed)
// time: O(n), where n is min(newsize, oldsize)
Amortized Cost / Doubling Strategy:
- Amortized = spreading the cost over many iterations
readstr()in but we need it to be- We allocate twice the memory we need, and only call
reallocwhen the array is “full”, in which case we double the length - We need to keep track of actual length and allocated length
- Resizing time is
1,2,0,4,0,0,0,8,0,0,0,0,0,0,0,16,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,32 - Total resizing time is
8.3 | ADTs in C and Amortized Analysis
ADT (Abstract Data Types)
- Information hiding provides security and flexibility
- Opaque structure: client cannot create an object unless we give them a make function
9 | Linked Data Structures
9.1 | Linked Lists
Like Racket lists: llnode is a recursive data structure
- Node contains item and pointer to next item
- Linked list nodes are not arranged sequentially because memory is allocated dynamically (when needed)
- Traversing list takes
Functions defined for llnode
list_createadd_frontlist_length- can be iterative or recursivelist_destroylist_dupinsertremove_front- similar toadd_front
// structure definition
struct llnode {
int item;
struct llnode *next;
};
struct llist {
struct llnode *front;
};
// cons(first,rest) creates and returns a list that
// contains first before rest
struct llnode *cons(int first, struct llnode *rest) {
// TODO: implement cons here.
struct llnode *node = malloc(sizeof(struct llnode));
node->data = first
node->next = rest;
return node;
}Whole linkedlist implementation
// this program demonstrates a variety of llist functions
// some of the documentation is conspicuously absent
// (sometimes this documentation is part of an assignment)
#include <assert.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
struct llnode {
int item;
struct llnode *next;
};
struct llist {
struct llnode *front;
};
// list_create() creates a new, empty list
// effects: allocates memory: call list_destroy
struct llist *list_create(void) {
struct llist *lst = malloc(sizeof(struct llist));
lst->front = NULL;
return lst;
}
// add_front(i, lst) adds i to the front of lst
// effects: modifies lst
void add_front(int i, struct llist *lst) {
assert(lst);
struct llnode *newnode = malloc(sizeof(struct llnode));
newnode->item = i; // add item
newnode->next = lst->front; // item points to front
lst->front = newnode; // item becomes new front
}
int list_length(const struct llist *lst) {
assert(lst);
int len = 0;
struct llnode *node = lst->front;
while (node) {
++len;
node = node->next;
}
return len;
}
void list_destroy(struct llist *lst) {
assert(lst);
struct llnode *curnode = lst->front;
struct llnode *nextnode = NULL;
while (curnode) {
nextnode = curnode->next; // set next
free(curnode); // free current node
curnode = nextnode; // move on to next
}
free(lst);
}
void list_print(const struct llist *lst) {
assert(lst);
struct llnode *curnode = lst->front;
if (curnode == NULL) {
printf("[empty]\n");
return;
}
while (curnode) {
printf("%d", curnode->item); //print cur
curnode = curnode->next; // go to next
if (curnode) {
printf("->");
}
}
printf(".\n");
}
struct llist *list_dup(const struct llist *oldlist) {
assert(oldlist);
struct llist *newlist = list_create();
if (oldlist->front) {
add_front(oldlist->front->item, newlist); // add front
const struct llnode *oldnode = oldlist->front->next; // initialize old
struct llnode *newnode = newlist->front; // initialize new
while (oldnode) {
newnode->next = malloc(sizeof(struct llnode)); // malloc
newnode = newnode->next; // move newnnode forward
newnode->item = oldnode->item; // set item
newnode->next = NULL; // set next
oldnode = oldnode->next; // move oldnode forward
}
}
return newlist;
}
// insert(i, slst) inserts i into sorted list slst
// requires: slst is sorted [not asserted]
// effects: modifies slst
// time: O(n), where n is the length of slst
void insert(int i, struct llist *slst) {
assert(slst);
if (slst->front == NULL || i < slst->front->item) {
add_front(i, slst);
} else {
// find the node that will be "before" our insert
struct llnode *before = slst->front;
while (before->next && i > before->next->item) {
before = before->next;
}
// now do the insert
struct llnode *newnode = malloc(sizeof(struct llnode));
newnode->item = i;
newnode->next = before->next;
before->next = newnode;
}
}
void remove_front(struct llist *lst) {
assert(lst);
assert(lst->front);
struct llnode *old_front = lst->front; // idk why really
lst->front = lst->front->next; // front = next
free(old_front);
}
// remove_item(i, lst) removes the first occurrence of i in lst
// returns true if an item is successfully removed
bool remove_item(int i, struct llist *lst) {
assert(lst);
if (lst->front == NULL) return false;z
if (lst->front->item == i) {
remove_front(lst);
return true;
}
struct llnode *before = lst->front;
while (before->next && i != before->next->item) {
before = before->next;
}
if (before->next == NULL) return false;
struct llnode *old_node = before->next;
before->next = before->next->next; // shift everything down
free(old_node);
return true;
}
// Demonstration of above functions:
int main(void) {
struct llist *lst = list_create();
list_print(lst);
add_front(23, lst);
add_front(16, lst);
add_front(8, lst);
list_print(lst);
printf("length of the list: %d\n", list_length(lst));
insert(15, lst);
insert(4, lst);
insert(42, lst);
list_print(lst);
struct llist *dup = list_dup(lst);
list_destroy(lst);
remove_front(dup);
remove_front(dup);
remove_item(23, dup);
list_print(dup);
list_destroy(dup);
}9.2 | Queue ADT
is just an extension of `llist
9.3 | Tree ADTs
void bstnode_insert(struct bstnode *n, int item){
if (item < n->item){ // must insert to the left
if (n->left == NULL) n->left = make_leaf(item);
else bstnode_insert(n->left, item);
} else if (item > n->item){ // right
if (n->right == NULL) n->right = make_leaf(item);
else bstnode_insert(n->right, item);
}
}
void bst_insert(struct bst *b, int item){
if (b->root == NULL){
b->root = make_leaf(item);
} else {
bstnode->insert(b->root, item);
}
}9.4 | Dictionary & Graph ADTs
Dictionary: pairs of keys and values Typical dictionary ADT operations:
- lookup: for a given key, retrieve the corresponding value or “not found”
- insert: adds a new key/value pair (or replaces the value of an existing key)
- remove: deletes a key and its value
10 | (Generic) Abstract Data Types
10.1 | ADT Design
In Computer Science, every data structure is some combination of the following “core” data structures:
- primitives (e.g. an
int) - structures (i.e.,
struct) - arrays
- linked lists
- trees
- graphs
Sequenced data = data where the sequence matters
Which data structure to use?
- Array = if you frequently access elements at specific positiosn
- Linked list = sequenced data, you frequently modify start and end
- Self-balancing BST = un-sequenced data, you frequently search, add, and remove
- Sorted array = if you rarely add/remove, but frequently search
Typically, the collection ADTs are implemented as follows.
- Stack: linked lists or dynamic arrays
- Queue: linked lists
- Sequence: linked lists or dynamic arrays. Some libraries provide two different ADTs (e.g., a list and a vector) that provide the same interface but have different operation run-times.
- Dictionary (and Sets): self-balanced BSTs or hash tables (an array of linked lists)
10.2 | Void pointers and Generic Functions
Void pointers (void *) is the closest C has to a “generic” type that can point at any data
- Avoid pointing a void pointer at a function
- Void pointers CANNOT BE DEREFERNECED
- Don’t confuse these with void functions (which return nothing)
mallocreturns a void pointer, that’s why it works for all types of data
int i = 42;
int *ip = &i;
struct posn p = {3, 4};
void *vp = NULL;
vp = &i; // int *
vp = &p; // struct posn *
vp = ip; // int *
vp = &ip; // int **
vp = &vp; // void ** (itself)You can indirectly dereference it
int i = 42;
void *vp = &i;
int *ip = vp; // vp points at an int
int j = *ip; // OK
*ip = 13;Generic functions that use void pointers:
qsort- sorts any data typebsearch- binary searchmemcpy- copies bytes from a source to a destination